Yes you can (on reads). if only reading off four disks would be 150 megabytes/sec which the disks are *NOT* capable of. Most raid controller I have seen will only read off half the disks in raid10 but areca will read from all the disks.
this tale is even more bizarre than i thought - the same arc-5020 box i was posting about before, now hooked via a port multiplier capable jmicron expresscard that lets me see both volumes on it.
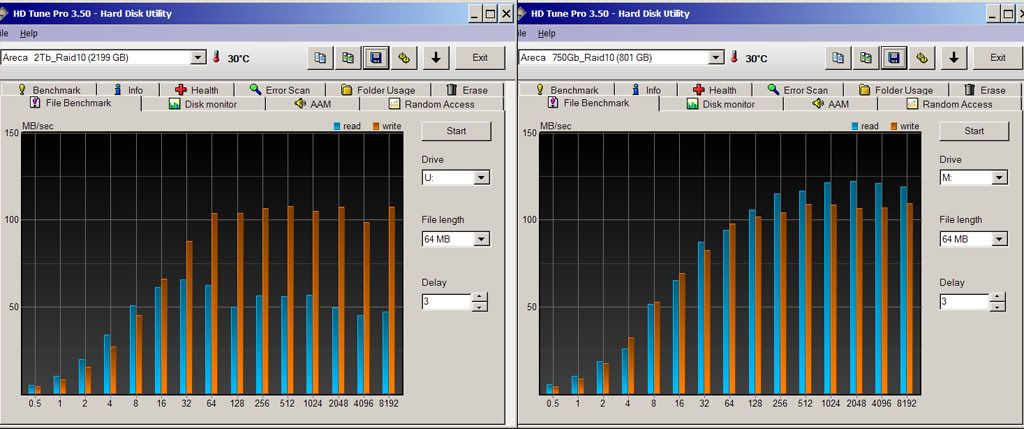
e.g. - the volume at the heads of the drives U: has the slow reads that i'd complained before, but the one at the tails, M: is ok. and M is 95% full now, U about 80%. i had thought that one of the HDs has some odd problem, but this kind of eliminates that. has to be something that the controller does, right?














