Shintai
Supreme [H]ardness
- Joined
- Jul 1, 2016
- Messages
- 5,678
How about Excavator? Seems to be getting big boost atleast. I doubt the boost is actually coming from 256bit.
Got any numbers from it running on 2.78.4?
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
How about Excavator? Seems to be getting big boost atleast. I doubt the boost is actually coming from 256bit.
Got any numbers from it running on 2.78.4?

why the hell are you now talking about 256bit and different versions now? its got nothing to do with the original test and what we were supposed to compare. or did amd release new tests and Su issue another challenge to compare 256bit blender that I missed? or are you just going way off base for no apparent reason?
")
did amd make any claim about that? not that I saw. in the new horizon video Su doesn't say shit about IPC, she does say blender "scales well with cores and threads"...Stock 6700K using Blender with 256bit AVX2. 100 samples. 27.17seconds!
that's really only used for HPC though isn't it?single cycle 256bit ops
that's really only used for HPC though isn't it?
so what are some real world applications then and how does this really affect the average user? why do you really care so much? tell us why we should, in normal laymen's terms.Not at all. Its a lot more used than people think. If it can benefit from SSE it can benefit from AVX. You also got compilers with autovectorization including MS.
https://msdn.microsoft.com/en-us/library/hh872235.aspx
so what are some real world applications then and how does this really affect the average user? why do you really care so much? tell us why we should, in normal laymen's terms.
beside, all the remours ive seen say it supports 256 and 512bit avx anyways. we haven't seen those demoed so I don't get what you are trying to prove without that info. reguardless, as I said before, it wasn't demoed nor offered as a challenge.



I haven't seen anything but arguing and honestly skipped a bunch. I just want a simple answer not "go look for it". I don't see why I should care about all this, so tell me why we should care, in easy simple terms. cause those slide don't really mean shit to me and I don't see this two cycles part youre hung up on. so explain it in simple terms, why should we care? does it improve encoding, make games faster? or is it only for like med research, f@h and shit that normal people don't use? instead of tech-babble make it clear and simple.Its already explained in the previous post.
512bit AVX is only Xeon Phi and Skylake-EP.
256bit AVX is supported, but it takes 2 cycles. Haswell, Skylake, Kaby Lake and Xeon Phi does it in 1 cycle.
AMDs own slides also confirms it.
One of the issues with single cycle execution is it requires a lot of bandwidth in the caches. And that uses power.
I haven't seen anything but arguing and honestly skipped a bunch. I just want a simple answer not "go look for it". I don't see why I should care about all this, so tell me why we should care, in easy simple terms. cause those slide don't really mean shit to me and I don't see this two cycles part youre hung up on. so explain it in simple terms, why should we care? does it improve encoding, make games faster? or is it only for like med research, f@h and shit that normal people don't use? instead of tech-babble make it clear and simple.
honestly to me it just seems like you are grasping at anything and everything that will take away from the good and make it look bad.
the only uses ive found for avx have been research, medical f@h and stuff like that. and the only game related is in PhysX. so not much normal use. it was the same in 2010, 2014 and earlier this year(threads I found while looking) avx/avx2 are available but not being used much and the average person shouldn't really care. the only game that I know of that has avx is grid 2 and it makes ZERO difference there. so still not seeing why I/we should care...
edit: there was already this avx discussion on [H] back in 2010 and 2014, minimal uses found. but yes IF avx/2 are used back then amd did not perform quite as good as intel. but that makes sense, its an intel tech. just like gameworks is nv and does not work well on amd.

the only uses ive found for avx have been research, medical f@h and stuff like that. and the only game related is in PhysX. so not much normal use. it was the same in 2010, 2014 and earlier this year(threads I found while looking) avx/avx2 are available but not being used much and the average person shouldn't really care. the only game that I know of that has avx is grid 2 and it makes ZERO difference there. so still not seeing why I/we should care...
edit: there was already this avx discussion on [H] back in 2010 and 2014, minimal uses found. but yes IF avx/2 are used back then amd did not perform quite as good as intel. but that makes sense, its an intel tech. just like gameworks is nv and does not work well on amd.
see now you bring up something completely different to try and continue.Whats next, x87 to SSE didn't do anything either? I get it, you dont like AVX and I know why. But that doesn't mean its not commonly used. Its not like applications and games comes with a checkbox list if they support SSE, AVX etc or not for the consumer to see easily. Vectorization is commonly used.
http://forums.steampowered.com/forums/showthread.php?t=2321925
was that on gpu?I actually wonder why anyone would use the CPU for rendering in Blender...
snipped pic
^^Black Desert Online was running on background, although minimised.
Yes. By the way, it's about 11 times faster on my system than using the i7-3770K @ 4,4 GHz. So, even with 1000 samples it's faster than my CPU with 150 samples (quality difference would be pretty huge).was that on gpu?
I actually wonder why anyone would use the CPU for rendering in Blender...
.
My rig is in my sig and I always refer to it unless I say otherwise. For GPUs you need to increase the tile size, a lot.You don't say what GPU you were using, I ran it with SLI Titan X Maxwells @ 1500 and it took roughly twice as long as it did with my CPU - but I admit I don't know much about Blender and might not have had the correct settings applied.
My rig is in my sig and I always refer to it unless I say otherwise. For GPUs you need to increase the tile size, a lot.
X86 instructions have hit a wall for IPC (Instructions per clock), MMX double the speed of integer type instructions and AVX (128bit) once again about double the speed by making them wider as in more data in the extended instruction. AVX 2 (256 bit, Intel supported since Haswell, AMD Excavator and Zen) once again double amount of data/instruction in the cpu which for very limited type of calculations (ones that are done over and over again like in a rendering program and can stay inside of the cpu caches etc.) AVX 512 (Intel Phi and Skylake E) again is a doubling the width of data and potential of doubling the speed of those calculations.see now you bring up something completely different to try and continue.
I don't dislike avx, I really have no idea where its being used and why you think it is such a big deal. its barely used in the normal world. the only game related ive seen is PhysX and grid 2. I don't know a single program that uses it and as ER470 just said, amd supports it, its just not as fast.
was that on gpu?
Since you have to change the settings anyway to be able to use GPU rendering it's better to do it properly. Tile settings that are optimal for CPU are not optimal for GPU, far from it.See, I was trying to run the file without altering any parameters. And sorry about missing your rig.
It's not possible since Summit Ridge doesn't have GPU. Secondly Friz chess benchmark doesn't support GPU compute (nor does it support HSA). GPU computing is not magic that suddenly works.As one person mention it is quite possible that the Ryzen which has gpu core built in cpu somehow utilizes resources of gpu to help cpu in this test.
Anyway we will wait for a new tests of Ryzen in the benchmarks, games and applications.
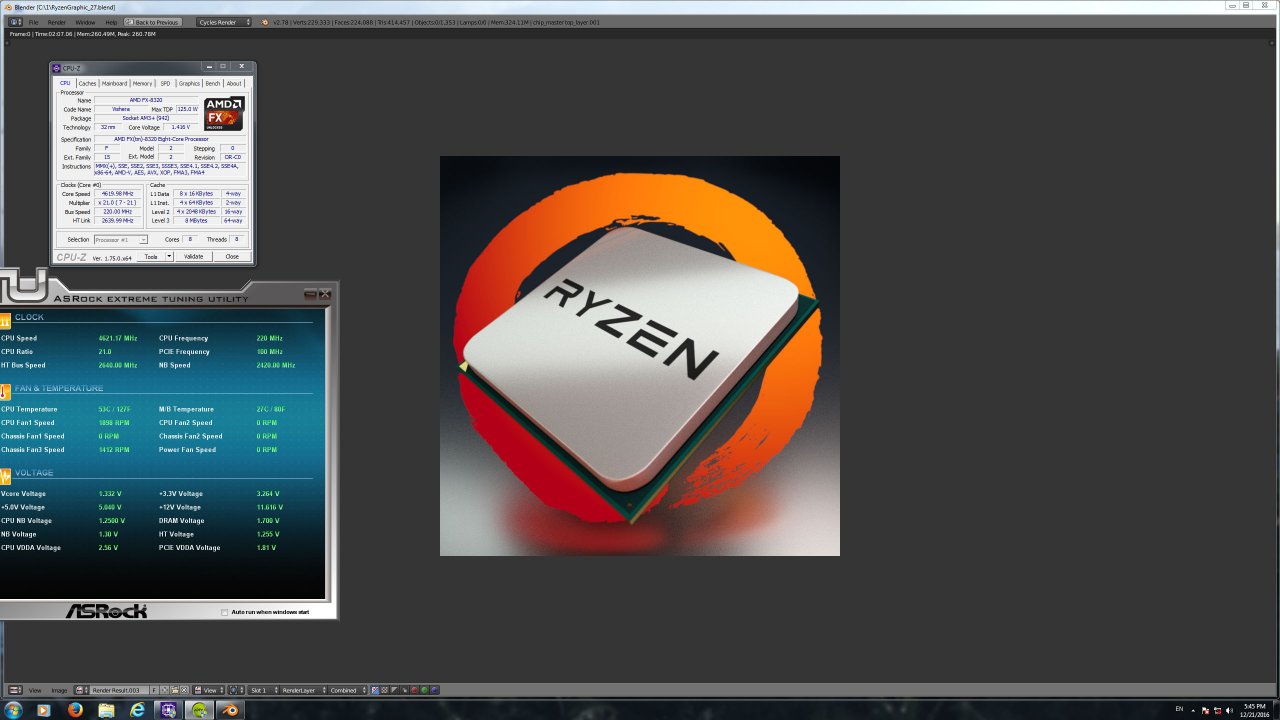
As Shintai said, the official Blender build is, if The Stilt's builds are credible, extremely inefficiently compiled for Piledriver.My AMD FX8320 @4600 (DDR3 2100) got 150 samples in 2min 07 sec. Probably the results could be better. I switched off all options like cool and quiet, C6 state and etc. in BIOS. I would like to mention that the thermal throttling was on a couple times and set the cpu to 1.5 GHz (cpu-z was on) when the temperature was over 55C.
I am pretty sure that the sample of AMD FX@4600 which shown 2min 35 sec in this test had a very bad cooling system and throttled too much.
I had the same result at my first try, but I opened the case and put an extra side fan 280 mm. The occurrence of thermal throttling decreased. I have a tower cooler V8.
see now you bring up something completely different to try and continue.
I don't dislike avx, I really have no idea where its being used and why you think it is such a big deal. its barely used in the normal world. the only game related ive seen is PhysX and grid 2. I don't know a single program that uses it and as ER470 just said, amd supports it, its just not as fast.
was that on gpu?
Where is the point at which it becomes more efficient to use a GPU to do vector processing rather than the CPU?Any software that benefits from SSE benefits from AVX, AVX is a natural extension of increasing 3d vectorizing in pipeline by going wider, that is all it is. AVX doubles the amount of register space available to do operations. Yeah they do have new primitives and data manipulation techniques but those won't come into play for older software.
Performance will never be a perfect increase of 2 fold because of this (older programs) but old programs still gets some benefit from it.
agner said:Current processors with the AVX2 instruction set have 16 vector registers of 256 bits each. The forthcoming AVX-512 instruction set gives us 32 vector registers of 512 bits each, and we can expect future extensions to 1024 or 2048-bit vectors. But these increases in vector size are subject to diminishing returns. Few calculation tasks have enough inherent parallelism to take full advantage of the bigger vector registers. The 512-bit vector registers are connected with a set of mask registers, which have a size limitation of 64 bits. A 2048-bit vector register will be able to hold 64 single-precision floating point numbers of 32 bits each. We can assume that Intel have no plans of making vector registers bigger than 2048 bits because they would not fit the 64-bit mask registers.
Where is the point at which it becomes more efficient to use a GPU to do vector processing rather than the CPU?
Strange, then, how the Lynnfield Blender results don't show gain from The Stilt's custom builds but more recent Intel CPUs and FX do. The latter in particular shows a really big gain. I think the biggest gain came from using Intel's own compiler.Now when you have vastly different architectures, like BD and Intel's crop, where one has AVX and the other one (BD) even though it has it, is badly bottlenecked else where, really only way to write the software, go Intel's route the get the most performance, because going BD's route, would just hurt the software with no real return since the developer has to still support older architectures, they can't go wider on the cores.
Strange, then, how the Lynnfield Blender results don't show gain from The Stilt's custom builds but more recent Intel CPUs and FX do. The latter in particular shows a really big gain. I think the biggest gain came from using Intel's own compiler.
Yeah, it looks like the Blender devs haven't managed to leverage instruction set that came out with Sandy and Bulldozer.As I stated before it could be because of different extensions, primitives, and data manipulation techniques in AVX vs SSE.
It's not possible since Summit Ridge doesn't have GPU. Secondly Friz chess benchmark doesn't support GPU compute (nor does it support HSA). GPU computing is not magic that suddenly works.
Rumors are that Ryzen APU processors will have comparable graphics performance to PlayStation 4".
Even with DDR4 the bandwidth is likely only 50-60GB/s which is to low. AMD can bypass the limitation two ways.
1) Use of EDRAM or L4 Cache like Iris Pro which is rediculously expensive.
2) Use of HBM which is expensive also and will need a special platform with more interconnect to allow the CPU to use both HBM and DDR4.
Right now I doubt AMD will use HBM, maybe in a couple years they will finally move to HBM on chip.